 Home-theater-designers
Home-theater-designers
Als data-analist krijg je vaak te maken met de noodzaak om meerdere datasets te combineren. U moet dit doen om uw analyse te voltooien en tot een conclusie te komen voor uw bedrijf/belanghebbenden.
Het is vaak een uitdaging om gegevens weer te geven wanneer deze in verschillende tabellen zijn opgeslagen. In dergelijke omstandigheden bewijzen joins hun waarde, ongeacht de programmeertaal waaraan u werkt.
hoe bestanden tussen Google Drives te verplaatsenMAKEUSEVAN VIDEO VAN DE DAG
Python-joins zijn als SQL-joins: ze combineren datasets door hun rijen op een gemeenschappelijke index te matchen.
Maak twee dataframes ter referentie
Om de voorbeelden in deze handleiding te volgen, kunt u twee voorbeeld-DataFrames maken. Gebruik de volgende code om het eerste DataFrame te maken, dat een ID, voornaam en achternaam bevat.
import pandas as pd
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber"]})
print(a)Importeer voor de eerste stap de panda's bibliotheek. U kunt dan een variabele gebruiken, a , om het resultaat van de DataFrame-constructor op te slaan. Geef de constructor een woordenboek met de vereiste waarden.
Geef ten slotte de inhoud van de DataFrame-waarde weer met de afdrukfunctie, om te controleren of alles eruitziet zoals u zou verwachten.
Op dezelfde manier kunt u een ander DataFrame maken, b , die een ID en salariswaarden bevat.
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(b)U kunt de uitvoer controleren in een console of een IDE. Het zou de inhoud van uw DataFrames moeten bevestigen:
Hoe verschillen joins van de samenvoegfunctie in Python?
De panda-bibliotheek is een van de belangrijkste bibliotheken die u kunt gebruiken om DataFrames te manipuleren. Omdat DataFrames meerdere datasets bevatten, zijn er verschillende functies beschikbaar in Python om ze samen te voegen.
Python biedt onder andere de functies samenvoegen en samenvoegen die u kunt gebruiken om DataFrames te combineren. Er is een groot verschil tussen deze twee functies, waar u rekening mee moet houden voordat u ze gebruikt.
De join-functie voegt twee DataFrames samen op basis van hun indexwaarden. De samenvoegfunctie combineert DataFrames gebaseerd op de indexwaarden en de kolommen.
Wat moet u weten over joins in Python?
Voordat we de beschikbare soorten joins bespreken, zijn hier enkele belangrijke dingen om op te merken:
- SQL-joins zijn een van de meest elementaire functies en zijn vrij gelijkaardig aan de joins van Python.
- Om lid te worden van DataFrames, kunt u de panda's.DataFrame.join() methode.
- De standaard join voert een left join uit, terwijl de merge-functie een inner join uitvoert.
De standaardsyntaxis voor een Python-join is als volgt:
DataFrame.join(other, on=None, how='left/right/inner/outer', lsuffix='', rsuffix='',
sort=False)Roep de join-methode aan op het eerste DataFrame en geef het tweede DataFrame door als de eerste parameter, ander . De overige argumenten zijn:
- Aan , die een index noemt om aan mee te doen, als er meer dan één is.
- hoe , welke definieert het join-type, inclusief inner, outer, left en right.
- lachtervoegsel , welke definieert de linker achtervoegselreeks van uw kolomnaam.
- achtervoegsel , welke definieert de rechter achtervoegselreeks van uw kolomnaam.
- soort , welke is een boolean die aangeeft of het resulterende DataFrame moet worden gesorteerd.
Leer de verschillende soorten joins in Python te gebruiken
Python heeft een paar join-opties die je kunt oefenen, afhankelijk van de behoefte van het uur. Dit zijn de join-typen:
1. Linker deelname
De linker join houdt de waarden van het eerste DataFrame intact en haalt de overeenkomende waarden van de tweede binnen. Als u bijvoorbeeld de overeenkomende waarden van b , kunt u het als volgt definiëren:
mac desktop gaat niet aan
c = a.join(b, how="left", lsuffix = "_left", rsuffix = "_right", sort = True)
print(c)Wanneer de query wordt uitgevoerd, bevat de uitvoer de volgende kolomverwijzingen:
- ID_links
- Fnaam
- Lnaam
- ID_right
- Salaris
Deze join haalt de eerste drie kolommen uit het eerste DataFrame en de laatste twee kolommen uit het tweede DataFrame. Het heeft gebruik gemaakt van de lachtervoegsel en achtervoegsel waarden om de ID-kolommen van beide datasets te hernoemen, zodat de resulterende veldnamen uniek zijn.
De uitvoer is als volgt:

2. Rechts meedoen
De juiste join houdt de waarden van het tweede DataFrame intact, terwijl de overeenkomende waarden uit de eerste tabel worden ingevoerd. Als u bijvoorbeeld de overeenkomende waarden van a , kunt u het als volgt definiëren:
c = b.join(a, how="right", lsuffix = "_right", rsuffix = "_left", sort = True)
print(c)De uitvoer is als volgt:
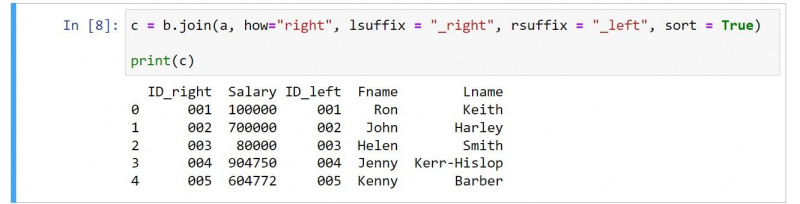
Als u de code bekijkt, zijn er een paar duidelijke wijzigingen. Het resultaat bevat bijvoorbeeld de kolommen van het tweede DataFrame vóór die van het eerste DataFrame.
U moet een waarde van gebruiken Rechtsaf voor de hoe argument om een juiste join op te geven. Let ook op hoe u de lachtervoegsel en achtervoegsel waarden om de aard van de juiste join weer te geven.
Bij uw normale joins zult u wellicht vaker linker-, inner- en outer-joins gebruiken dan de rechterjoin. Het gebruik hangt echter volledig af van uw gegevensvereisten.
3. Innerlijke verbinding
Een inner join levert de overeenkomende vermeldingen van beide DataFrames. Aangezien joins de indexnummers gebruiken om rijen te matchen, retourneert een inner join alleen rijen die overeenkomen. Laten we voor deze illustratie de volgende twee DataFrames gebruiken:
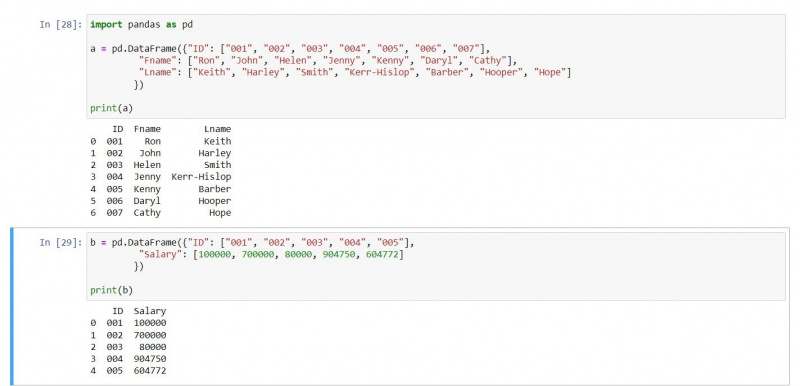
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005", "006", "007"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny", "Daryl", "Cathy"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber", "Hooper", "Hope"]})
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(a)
print(b)De uitvoer is als volgt:
hoe toegang te krijgen tot Instagram-berichten op de computer
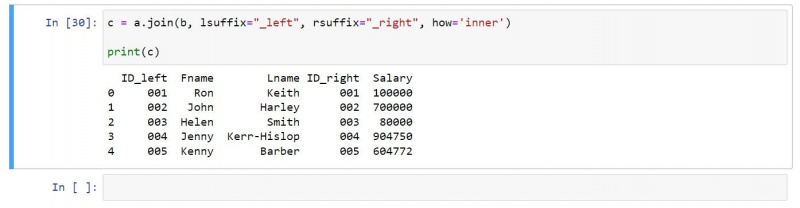
U kunt een inner join als volgt gebruiken:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='inner')
print(c)De resulterende uitvoer bevat alleen rijen die in beide invoer-DataFrames voorkomen:
4. Buitenste verbinding
Een outer join retourneert alle waarden van beide DataFrames. Voor rijen zonder overeenkomende waarden produceert het een null-waarde voor de afzonderlijke cellen.
Gebruik makend van hetzelfde DataFrame als hierboven, hier is de code voor outer join:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='outer')
print(c)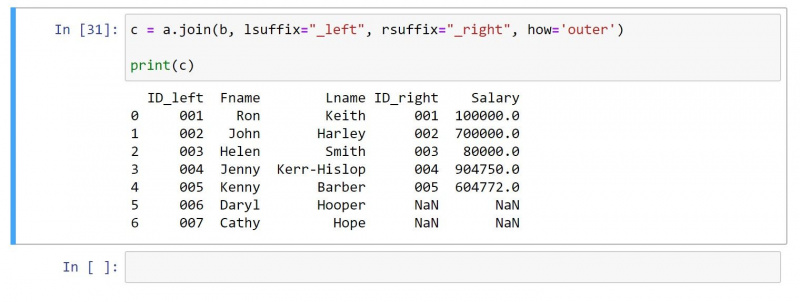
Joins gebruiken in Python
Joins bieden, net als hun tegenhangerfuncties, merge en concat, veel meer dan een simpele join-functionaliteit. Gezien de reeks opties en functies kunt u de opties kiezen die aan uw eisen voldoen.
Je kunt de resulterende datasets relatief eenvoudig sorteren, met of zonder de join-functie, met de flexibele opties die Python biedt.